

La implantación progresiva de la Historia Clínica Electrónica en los sistemas de salud a lo largo de todo el mundo, incluida España, trajo consigo grandes avances en el almacenamiento, acceso y seguridad de la información clínica en el sistema sanitario, con importantes beneficios en la calidad asistencial. En el año 2022 se estima que solo en España se atendieron 262M de consultas de Atención Primaria, 191M de Enfermería y 82,1M de Atención Hospitalaria. Cada una de ellas, probablemente ha generado un registro digital con las anotaciones del sanitario que las ha realizado.
La siguiente frontera se estableció, y sigue estando, en el aprovechamiento y procesamiento eficaces y eficientes de toda la información que se acumula, casi en tiempo real, con el fin de generar nuevo conocimiento, desarrollar políticas preventivas de enfermedades crónicas, vigilar la calidad asistencial o desarrollar incluso alertas automatizadas. Sin embargo, la presencia de información “no estructurada”, especialmente en forma de imagen y narrativas clínicas en texto libre (informes médicos, radiológicos, patológicos, anotaciones de enfermería, etc.), siempre ha supuesto un reto para la extracción de información de forma automatizada y su ulterior aprovechamiento en las vías antes mencionadas.
Claves del procesamiento de texto
Centrándonos en texto libre en general y en el texto médico/clínico en particular, su procesamiento implica enfrentarse a aspectos y matices complejos, como la presencia de acrónimos, lenguaje técnico, detección de negaciones y/o especulaciones, desambiguación de términos, errores ortográficos, empleo de múltiples idiomas, entre otros. Estos desafíos vienen siendo abordados mediante técnicas del ámbito del “procesamiento del lenguaje natural” (NLP, Natural Languaje Processing), a su vez muchas veces apoyadas por métodos de aprendizaje automático (ML, Machine Learning), con el fin de realizar tareas complejas sobre narrativas clínicas en texto libre, como extraer información relevante de una narrativa clínica dada (“¿qué síntomas presentaba el paciente según esta historia?”) o realizar predicciones sobre la misma (“¿esta historia implica que el paciente tenga riesgo de sepsis?”). Sin embargo, el desarrollar un sistema capaz de llevar a cabo esta tarea sobre texto natural implica siempre el diseño de procesos complejos y ad-hoc, que incluyen: (i) preprocesamiento del texto, donde se realizan transformaciones específicas así como la extracción de características para representar el texto de forma estructurada y (ii) procesos de entrenamiento y validación de algoritmos, con el fin de que estos identifiquen y exploten los patrones relevantes en los textos convenientemente transformados. Para ello, se requieren siempre de un elevado número de “ejemplos” de entrenamiento. Sin embargo, este contexto está experimentando un cambio de paradigma por la irrupción de modelos largos de lenguaje (o LLM por sus siglas en ingles). Los LLM constituyen el pilar sobre el cual se edifican los chatbots más avanzados y sofisticados de la actualidad, tales como ChatGPT, Gemini, o LLaMa2. Esta nueva tecnología ha sido posible por el avance científico que supuso incorporar un “mecanismo de atención” en las redes neuronales, que les permite, no solo modelar información secuencial a un nivel sin precedentes, como lo es el lenguaje natural, al posibilitar el aprendizaje de la influencia que tienen unas palabras sobre otras en un texto a procesar, sino también hacer viable su entrenamiento sobre vastos corpus de documentos procedentes de diversas fuentes, incluyendo la web, Wikipedia, artículos científicos, patentes y noticias, entre otros. Este nivel de sofisticación en la interacción y el procesamiento no solo mejora significativamente la eficiencia y la efectividad en la gestión de la información, sino que también enriquece la toma de decisiones al proporcionar contextos y explicaciones claras detrás de cada respuesta realizada. Este avance marca un hito en la evolución de la IA aplicada, especialmente en el ámbito médico, donde uno de los requisitos fundamentales ha sido superar la naturaleza opaca de los modelos tradicionales, que a menudo eran percibidos como una “caja negra”.
Las claves de ClinIA
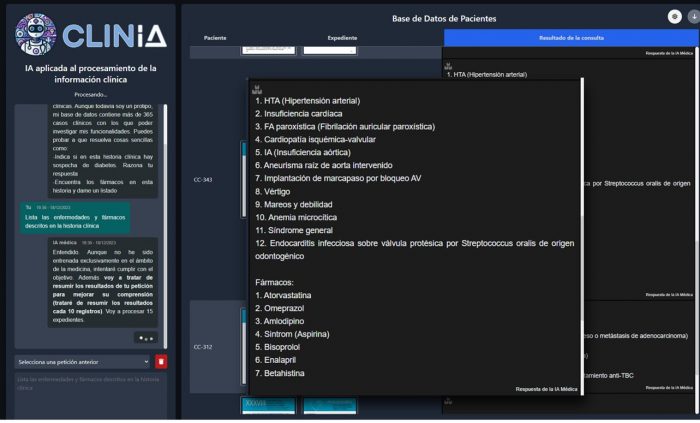
En este contexto, nace el proyecto ClinIA . ClinIA surge con el propósito de convertirse en una plataforma para el desarrollo a bajo coste de agentes con capacidad de procesamiento y extracción de información automática a partir de narrativas clínicas: Documento (narrativa clínica) + prompt (instrucción del usuario) = Tarea. El objetivo principal es realizar tareas sobre documentos de forma masiva, que bien por su complejidad o por el gran volumen de datos involucrados, resultan extremadamente tediosas o directamente inviables para el personal sanitario. La visión que guía el desarrollo y la integración de la ClinIA en el ámbito de la salud no es la de sustituir el juicio humano, sino la de ampliar y enriquecer las capacidades de los profesionales y/o del sistema sanitarios. Todo ello abordando nuevas tareas de explotación de la historia clínica electrónica, inviables hasta el momento por su elevado coste material y humano. Las ventajas de este nuevo enfoque sobre el tradicional modelo de procesamiento de textos médicos son numerosas:- No se precisa re-entrenar el modelo para cada problema concreto. Un cambio de prompt en ClinIA, implica un cambio de tarea a la cual el modelo es capaz de adaptarse, desde: “extrae los fármacos de esta historia clínica”, pasando por “dime si el paciente tiene riesgo de reingreso y justifica tu respuesta”, hasta “clasifica la siguiente historia clínica en: enfermedad infecciosa Sí/No”.
- El modelo es capaz de esgrimir una justificación si así se lo requerimos, por lo que ya no se percibe como una 'caja negra', ayudando a intuir cómo mejorar los propios prompt e, incluso, contribuir a alcanzar mejores respuestas del propio modelo.
- Es relativamente económico, dado que se basa en los modelos LLM “free weights” como LLaMa2 o Mixtral, que muestran capacidades cada vez más cercanas a las de ChatGPT4 y los cuales son descargables de forma gratuita y ejecutables en tu propia infraestructura computacional.
- Cada hito que se produzca en la comunidad científica en torno a los LLM es una aportación que se puede incorporar fácilmente a ClinIA. Mejores modelos implica: abordar tareas más complejas y mejores resultados.